Simulating detection of COVID-19 with wastewater MGS
Author
Dan Rice
Published
August 25, 2025
Modified
August 28, 2025
Objective
To get a very rough answer to the question: If a wastewater MGS surveillance system had been operational in 2020, when would it have detected SARS-CoV-2 reads?
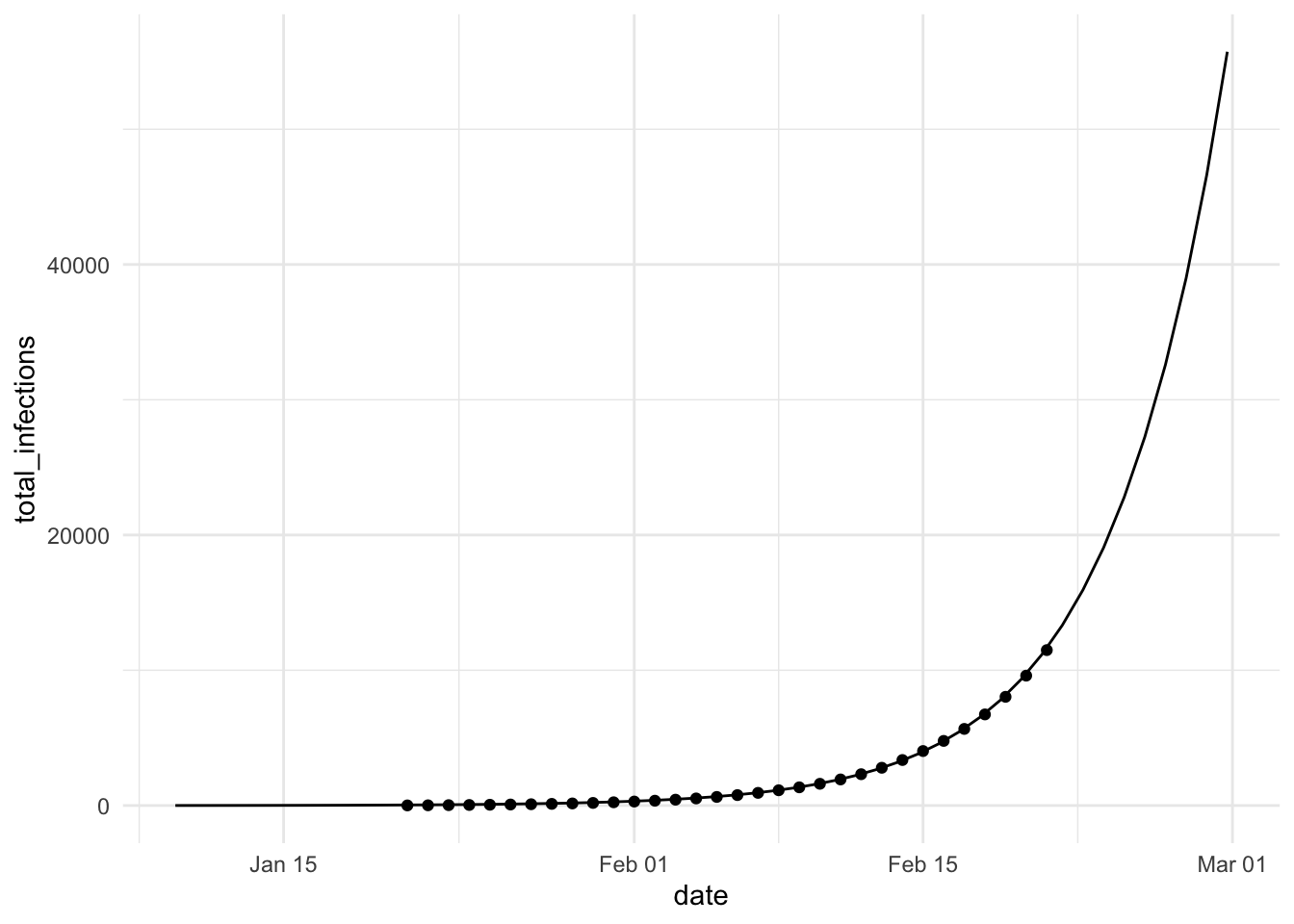
A single deterministic incidence curve for one population
Exponential growth for two months starting from a single case
NOT an SIR model, but exponential growth of incidence is an intermediate-time approximate solution to SIR
simulate_epidemic <-function( population_size, doubling_time, # in days day_zero # date when incidence = 1 case){ growth_rate <-log(2) / doubling_time max_day <-60tibble(day =0:max_day,date = day_zero + day,# Exponential growth from a single caseincidence =exp(day * growth_rate) / population_size,cumulative_incidence =cumsum(incidence),# slide_dbl includes the current day plus .before days before it.weekly_incidence =slide_dbl(incidence, sum, .before =6, .complete =FALSE), )}
Detection
Model reads as negative binomial with an expectation set by the weekly incidence, \(RA_i(1%)\), and the number of reads sequenced per sample.
Detection is based on observing at least detection_reads cumulative reads across all samples.
simulate_detection <-function( epi_sim, # output of `simulate_epidemic` num_sites, samples_per_site_per_day, ra_i_01, # expected relative abundance at 1% weekly incidence phi, # overdispersion parameter for read counts detection_reads, # number of cumulative reads required to detect virus delay_days, # days of delay between sample collection and detection reads_per_sample, ... # absorb unused parameters. allows us to use pmap with the full input data) { mu <- ra_i_01 *100 num_reps <-100 epi_sim %>%# For each day in the simulation, simulate num_reps replicates# of the daily sampling processcross_join(expand_grid(rep =1:num_reps,site =1:num_sites,sample =1:samples_per_site_per_day, ) ) %>%# Simulate readsmutate(expected_reads = weekly_incidence * mu * reads_per_sample,reads =rnbinom(n(), size = phi, mu = expected_reads), ) %>%# Add sites and samples togethersummarise(reads =sum(reads),.by = day:rep, ) %>%# Get cumulative reads per daymutate(cumulative_reads =cumsum(reads),.by = rep, ) %>%# Simulate detectionsummarise(threshold_day = day[which.max(cumulative_reads >= detection_reads)],detection_day = threshold_day + delay_days,.by = rep, ) %>%left_join( epi_sim,by =join_by(detection_day == day), ) %>%# Return median detection date and cumulative incidence across reps summarise(across(c(date, cumulative_incidence), median), )}
Parameters
Epidemic parameters
Start with the median estimated number of US infections from the SI of this paper.
Fit an exponential growth curve to the estimates to get growth rate and projected day when the first person was infected.
Use the Rothman \(RA_i(1\%)\) for SARS-CoV-2 as the baseline.
Also include a 10x increase as a proxy for airplane waste or an improvement in tech.
Require 5 reads for detection
ra_i_01_rothman <-6e-8# posterior median of Rothman SARS-CoV-2 in Grimm et al 2023sensitivity_params <-tribble(~sensitivity, ~ra_i_01,"rothman", ra_i_01_rothman,"10x rothman", ra_i_01_rothman *10,) %>%mutate(phi =1, # prior mode for wastewater phi in the swab p2ra blog postdetection_reads =5, )
Cost and sequencing parameters
Annual budget: $10M
Non-sequencing costs from this NAO quote private doc
budget_params <-expand_grid(annual_budget =10e6,budget_per_day = annual_budget /365,cost_per_sample =600, # ~$300 for consumables, ~$300 for wet lab labornonseq_cost_per_run =2300, # ~$2K for wet lab labor, $300 dry lab)non_sequencing_delay <-4# shipping, wet lab, computationsequencing_params <-tribble(~flow_cell, ~reads_per_run, ~seq_cost_per_run, ~delay_days,"10B", 10e9, 12e3, non_sequencing_delay +1,"25B", 25e9, 16e3, non_sequencing_delay +2, # Takes an extra day to run)
Sampling parameters
Sample daily from a number of sites.
We don’t want to oversequence the libaries, so say that after 1B reads sequenced from a sample, we don’t get any new information.
To get around this, we can sequence multiple samples from the same location on the same day. How many samples should we sequence per location per day?
Our budget also allows us to do at least one sequencing run per day. How many should we do?
Solve the constrained optimization problem:
Maximize the number of useful reads we get while staying under-budget.
Vary the number of runs per day and the number of samples per location per day.
max_reads_per_sample <-1e9# Can't get useful information from more than 1B reads per samplesampling_params <- budget_params %>%cross_join(sequencing_params) %>%cross_join(expand_grid(num_sites =c(5, 10),samples_per_site_per_day =seq(1, 10),runs_per_day =seq(1, 2), ) ) %>%mutate(cost_per_run = nonseq_cost_per_run + seq_cost_per_run,samples_per_day = num_sites * samples_per_site_per_day,samples_per_run = samples_per_day / runs_per_day,cost_per_day = runs_per_day * cost_per_run + samples_per_day * cost_per_sample,reads_per_sample =pmin(reads_per_run / samples_per_run, max_reads_per_sample),reads_per_day = reads_per_sample * samples_per_day, ) %>%# Only consider schemes that are under budgetfilter(cost_per_day <= budget_per_day) %>%# Take the scheme with the maximum total effective reads per dayslice_max( reads_per_day,by =1:num_sites, ) %>%# Break ties by lowest cost per dayslice_min( cost_per_day,by =1:num_sites, )sampling_params %>%select(flow_cell, num_sites, runs_per_day, samples_per_site_per_day, reads_per_sample) %>% print
Looks like we should always do one sequencing run, that the optimal number of samples per site per day varies with the flow cell and number of sites, and that we’ll end up oversequencing.
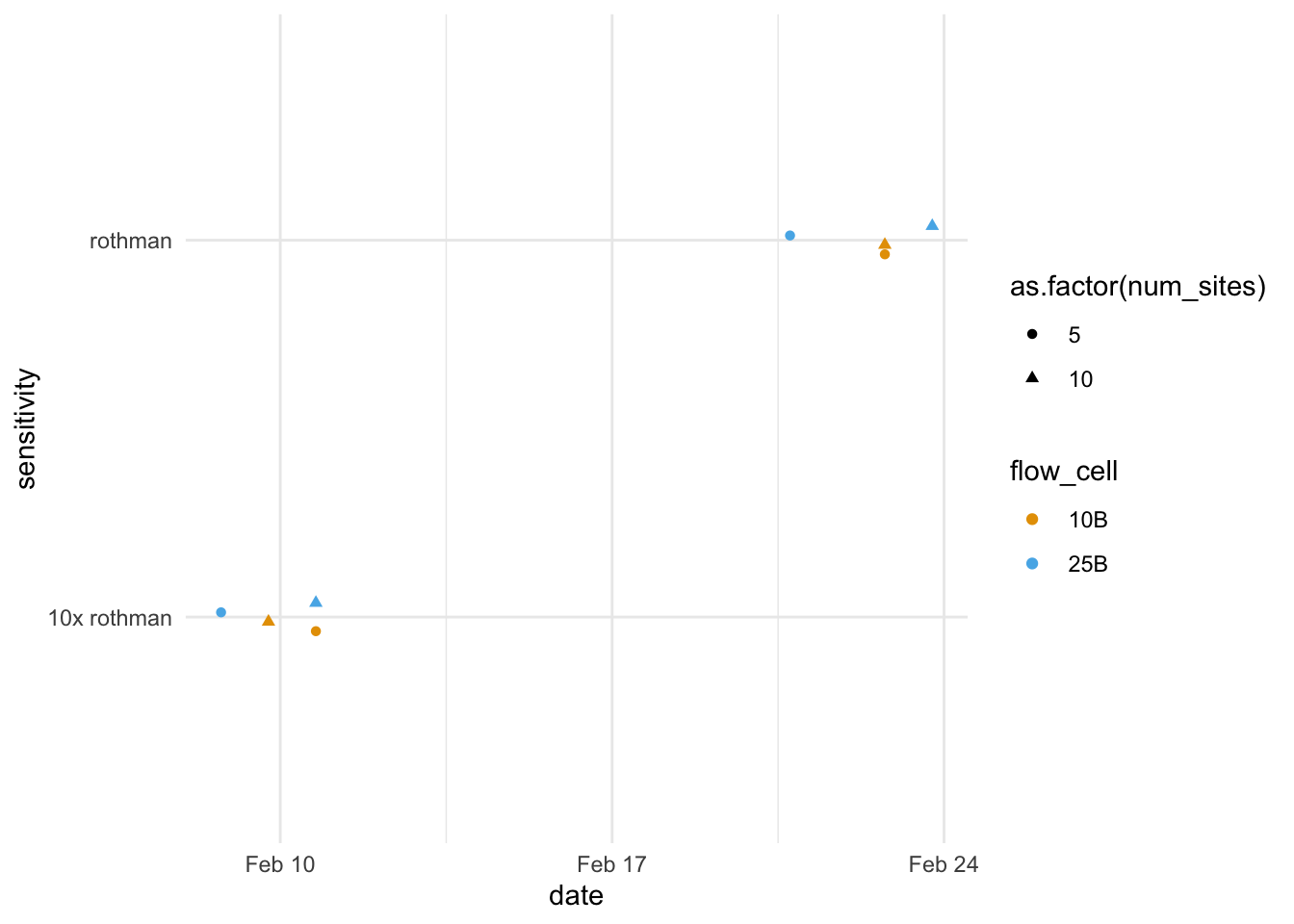
Simulation results
Run the simulation for every parameter combination.
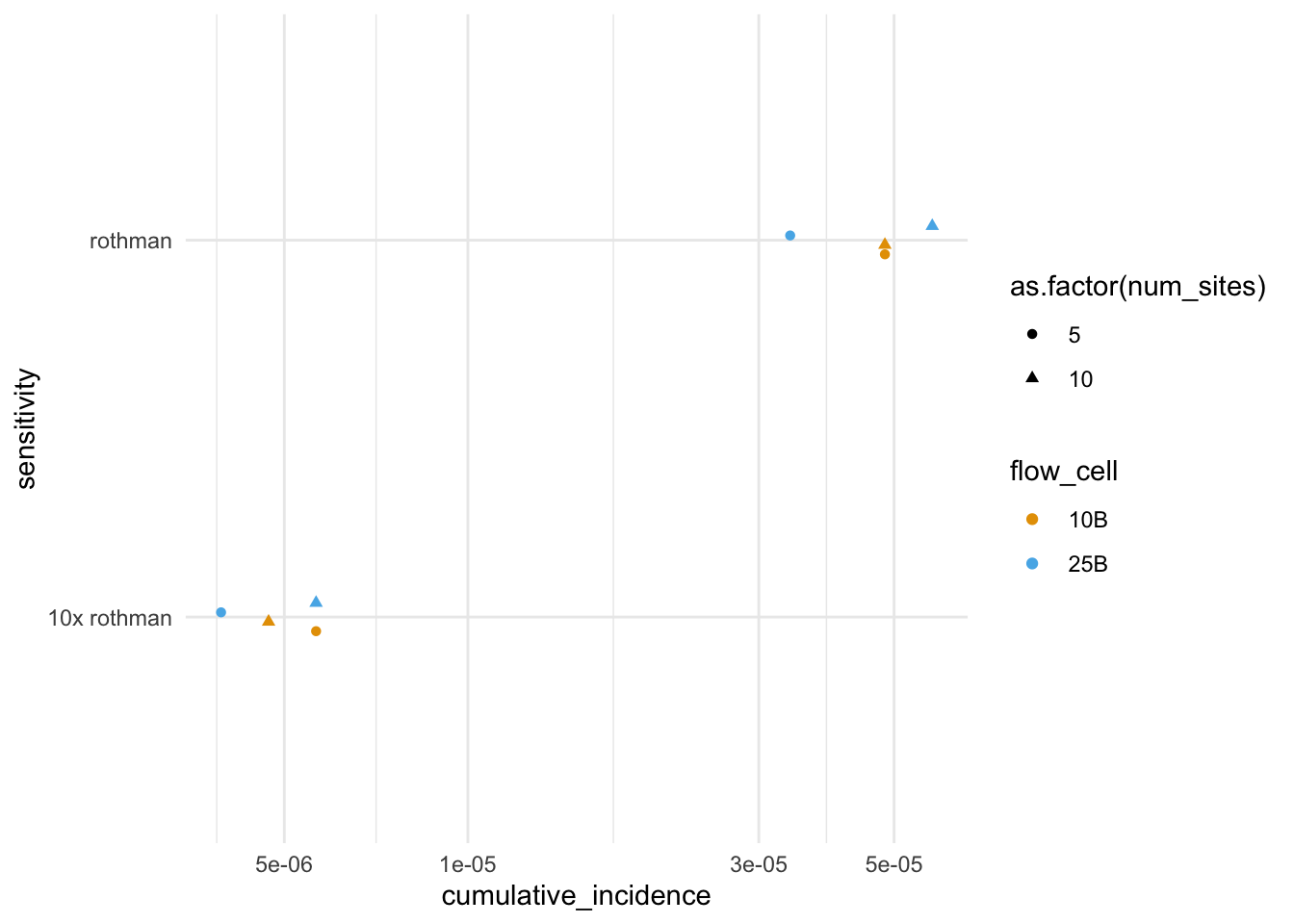
The 10x difference in sensitivity makes a big difference (as you’d expect). The flow cell and number of sites do not. Of course, our model doesn’t account for geographic variation in spread, so this is not surprising.
Detection cumulative incidence for different scenarios: